By David Dobbs
Read part 1 of our next generation API journey.
Domain Modeling and Documentation
As we were evolving our infrastructure, we were also brainstorming around a new domain model. Eventually we asked a few engineers to manifest our discussion notes into a domain model diagram. Our v1 endpoints revolved around a single domain whose ID was passed in every call. We knew we wanted more granularity for v2, and eventually we reached consensus on a domain model. We created a GitHub repo, “v2-api-contracts”, to iterate on open API specs. At the same time, we started building out a SwaggerHub site. We stood up a staging site and a production site on SwaggerHub. Developers could stage changes on SwaggerHub staging, and export that change into GitHub where a PR would be created and then go through the normal review process. Once the change was approved, we would copy the spec to SwaggerHub production. Eventually we established “public” and “private” domains. We started building services that would expose endpoints for the public domains. The private domains were built to assist with certain service to service use cases.
In addition to our V2 endpoints, we also published our notification Webhooks on SwaggerHub. Integrators now have documentation detailing our events and their corresponding open api specifications. As with our api endpoints, we provide sample payloads for all of our notification Webhooks. As part of our V2 API project, we built a new Webhook micro service. We store partner configurations as json in AWS S3. As the service detects an applicable Kafka event, it cycles through each partner configuration to determine if the partner has registered for that event. The detection service hands off to the delivery service to post the webhook data to the partner endpoint as per their configuration. Examples of our SwaggerHub documentation can be found here: https://joinmosaic.com/technology/developers/.
Planning and Execution
Although many engineers participated in the discovery phase of V2 API, most of the engineering teams were allocated to other projects. We identified a few engineers, a team lead, and a product manager and gave them a charter to work on the first set of endpoints. Thus, the API scrum team was born. Presenting disclosures to our borrowers during the credit application process is an important part of compliance. This data was previously hard coded into our various screens, so we thought this would be a good candidate to serve via the V2 API. The use case was relatively simple. We needed to create POST and PATCH endpoints to allow our internal user to load the disclosure content. Likewise, we would need a GET endpoint to serve the content to our api integrators as well as our own web portals. Our Monorepo CI/CD pipeline was not fully built out so we quickly realized that this team would need to build some infrastructure in addition to endpoints. The Disclosure Service was the first service to use CQRS in the “Lagom” way, so there was an additional technical opportunity. This team built up skills in these areas and in many ways these first few endpoints became a reference architecture for future services and endpoints.
Eventually other teams joined the V2 API initiative, and it was important to have effective cross team coordination. We started a “Scrum of Scrums” meeting twice per week where all teams working on the project come together to give updates and coordinate their work. We developed a master Google Sheet to track the project at a high level and appointed a Program Manager. We divided the delivery into 3 releases: Sycamore, Pine, Aspen to correspond to collections of endpoints to unlock various partners. Each release became a Jira Initiative, and there were no less than 4 Jira Projects which rolled under these initiatives.
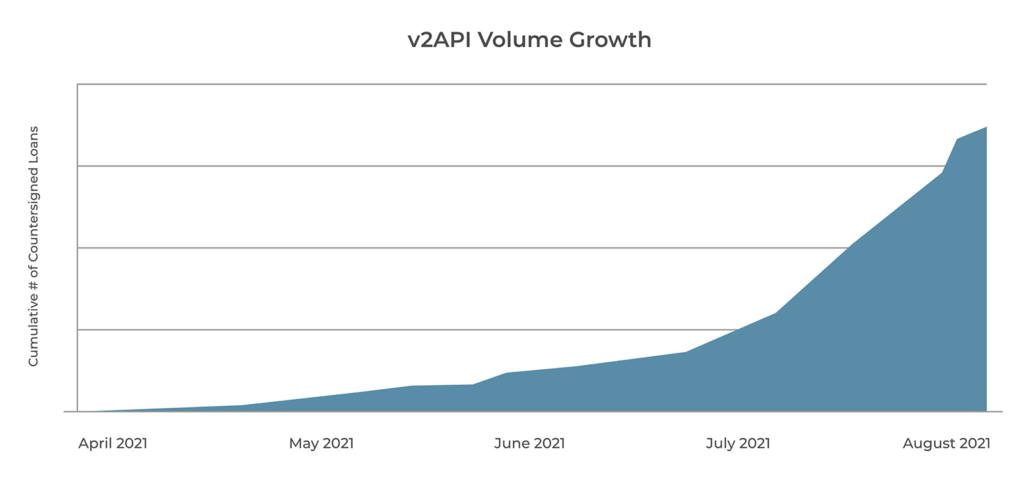
Partner Integrations
We had several SaaS partners and at least one tier 1 partner lined up to begin integrations as we were finishing Sycamore. We shared the SwaggerHub docs and set up meetings with product and engineering from these companies. For each integration, we set up a shared Slack channel so we could have real time communication and problem solving. Having a shared Slack channel was very helpful for providing examples of json payloads, and debugging logs. We were having ongoing conversations with our partners and several partners completed the integrations within a few weeks. As we engaged with our integration partners, we realized that we could not scale on the sales front with our current staff. We decided to hire a Sales Engineer. This was our first such engineer, and this person hit the ground running to understand our V2 API offerings. In short order, they were leading the calls with our partners and monitoring several Slack channels to provide white glove support.
For each partner, we built Sumo Logic reports so that our SE could very quickly identify any obstacles that needed attention. Likewise, we created a Periscope Dashboard which contained tables and visualizations of how each partner was evolving their loan volume.